

Is Your Enterprise “Agent-Ready”?
Enterprises don’t become “agent-ready” by picking the right framework or model; they become agent-ready when they consistently choose the right problems, have data and architecture that can support them, and can run automation in production with guardrails and ROI. In practice, this is how a rigorous enterprise AI readiness assessment should be evaluated.
As ClairX architects, we see a common pattern across mid-to-large enterprises in retail, financial services, energy, and beyond: the agentic AI conversation is arriving atop unresolved basics. Pilots look great in demos, but they stall when they meet messy data, fragmented ownership, brittle integrations, and unclear accountability.
This article lays out a practical, technology-agnostic checklist for “agent-readiness” seen through a data-first, architecture-led lens. Agents are treated as one kind of AI client in your ecosystem, not the centre of the universe. This could come across as an Agentic AI implementation checklist grounded in operational reality.
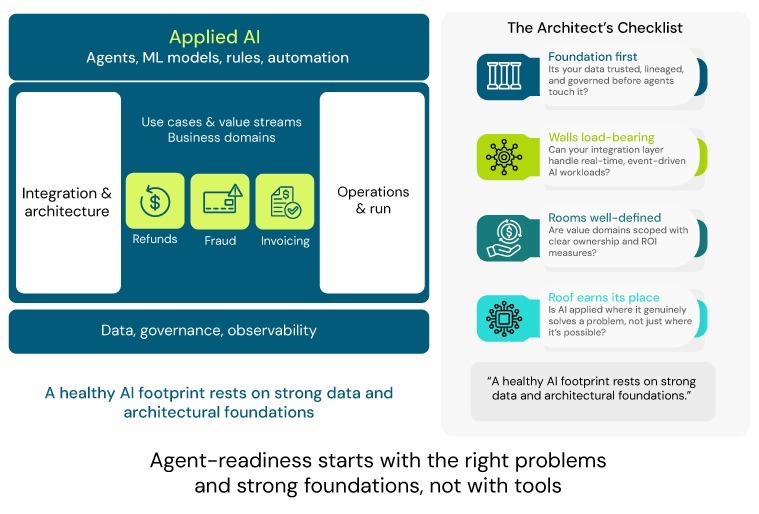
1. Agents Are a Means, Not the Goal
If the brief starts with “we want to do something with agentic AI”, you’re already off on the wrong foot. High-performing enterprises start with business problems and outcomes, then decide whether agents, traditional ML, rules, or simpler automation are the right tools.
Let’s look at use cases, outcomes, and ROI.
1.1 Problem first, technology second
For each prospective initiative, you should be able to write a one-line problem and outcome without naming a technology:
- Retail example: “Reduce refund handling time by 30% for straightforward cases, without increasing errors.”
- Financial services example: “Cut manual invoice matching effort by 50% while maintaining control and auditability.”
Useful checks:
- Can we name the specific process?
- Can we describe the pain in business terms (cost, risk, speed, experience)?
- Is there a single accountable business owner for the outcome?
1.2 Use-case selection and prioritisation
Most organisations have dozens of AI ideas and limited capacity. If you have too many ideas, filter ruthlessly among loosely defined use cases.
- Measurable value
- Clear link to revenue, cost, risk, capital, or working capital.
- Example (retail): return-processing efficiency, basket size, churn.
- Data & process readiness
- Data exists and is at least “good enough” to start.
- Process is repeatable today (even if manual), not reinvented weekly.
- Ownership
- A senior leader is willing to commit teams and drive process change.
- Regulatory feasibility
- The use case aligns with regulatory and ethical context (e.g., credit, pricing, HR decisions require stricter guardrails).
Typically, only 2–5 use cases per domain pass this filter per domain, — not 20.
1.3 ROI and value tracking
Before you build anything:
- Baseline
- Operational: handle time, backlog, error rate, rework.
- Experience: NPS/CSAT, abandonment, complaints.
- Financial: margin impact, losses, write-offs, FTE hours.
- Target ranges — e.g., “15–25% reduction in manual touches on refunds.”
- Measurement plan — How will realised benefits be calculated, over what period, and who signs off?
Without this discipline, agentic AI becomes an R&D and cloud-spend line item rather than a value-creation lever.
2. Data Foundations: Can Your Data Support Serious AI?
Most agent failures are simply familiar AI failures wearing new labels — incomplete data, conflicting definitions, brittle pipelines, and Excel in the middle.
Serious automation requires deliberate data readiness for AI agents, not just dashboards and reports.
2.1 Data inventory and lineage
Start with visibility:
- Do you have an inventory of core data domains (customers, products, orders, inventory, payments, assets, policies, transactions)?
- For each domain, can you trace:
- Systems of record (where it is mastered)
- Downstream systems and pipelines (where it flows)
- Transformations (how it is joined or enriched)
Retail example:
- Customer identity scattered across e-commerce, store loyalty, and email tools.
- No single place to see a unified view with lineage → any AI on “customer behaviour” is built on sand.
Red flags:
- Critical data exists only in reports or exports, not in accessible systems.
- You cannot answer “where does this field actually come from?” without detective work.
2.2 Data quality and semantics
AI (and agents) amplify whatever data you feed them.
Key checks:
- Are critical fields (IDs, dates, amounts, statuses, SKUs) monitored for completeness, consistency, and validity?
- Do business and technology teams share definitions for “active customer”, “churned”, “stock available”, “closed case”?
- Do you have data quality SLAs for high-impact datasets (e.g., transactions, inventory, claims)?
Useful metrics:
- Null or missing rates on key fields.
- Duplicate entities (customers, vendors, products).
- Timeliness (e.g., “inventory updates must be within 5 minutes for these channels”).
- Reconciliation between operational and finance systems.
2.3 Access patterns and latency
Agents and models do not work off static reports; they need machine-friendly access.
We need to ask:
- Can systems access data via APIs, query endpoints, or data products — or only through manual exports and spreadsheets?
- For each use case, what genuinely needs real-time versus batch?
- Retail: fraud, authorisations, certain pricing → near real-time.
- Monthly P&L, long-term forecasting → batch is sufficient.
We’ve seen many teams over‑engineer low‑value use cases with real‑time tech while critical processes run on CSVs and manual uploads.
2.4 From warehouse to vector- and semantic-enabled platform
Most enterprise platforms were built for BI and batch analytics — not for reasoning agents that require contextual retrieval and structured traversal.
Supporting agents requires deliberate evolution of your enterprise data architecture for AI agents, including vector retrieval and a pragmatic semantic layer. Strong Agentic AI architecture consulting extends your foundations responsibly rather than rebuilding everything.
Vector-native foundation (memory for AI):
- Introduce a vector store (or vector capabilities in your lakehouse/warehouse) alongside existing tables, with:
- Approximate nearest neighbour search
- Metadata filtering
- Hybrid semantic + keyword retrieval
- Latency and availability SLAs aligned to use cases
- Build embedding pipelines that:
- Extract text and key fields from tickets, emails, contracts, policies, product content, and logs.
- Generate embeddings using versioned models.
- Store embeddings with robust IDs, metadata, and sensitivity tags.
- Treat embeddings as governed derived data — retention, masking, residency, and access policies must apply.
Semantic layer (beyond table names):
Agents cannot navigate TBL_USR_01 or FCT_ORDERS_MTD; they need a business-level map of your data.
- Define canonical entity models in priority domains (Customer, Order, Product, Claim, Invoice, Asset, Case).
- Implement a lightweight semantic layer or knowledge graph that:
- Encodes relationships (Customer → Orders → Items → Returns; Policy → Claims → Payments).
- Exposes entities via APIs for traversal without hard-coded joins.
- Maintain a machine-readable catalogue of data products:
- Human-friendly names and business definitions.
- Programmatic discovery so an agent can answer “what data exists for customer behaviour in the last 30 days?” without spelunking schemas
You do not need to boil the ocean. You need vector and semantic capabilities in domains where agents will operate, with discipline to scale later.
What this means for your existing platform:
- If you already have a warehouse or lake:
- Add vector capabilities (either embedded or adjacent).
- Design and implement a lightweight semantic layer for priority domains.
- Tighten metadata, lineage and quality for the entities agents will use.
- If you’re still in “raw lake + reports” mode:
- Becoming agent‑ready is your forcing function to evolve towards a data platform that exposes well‑defined entities, metrics, and retrieval patterns—not just files and dashboards.
3. Governance and Control: Can You Trust What Agents Can Do?
As soon as agents can read and write across systems, governance shifts from “who can see data?” to “who can act with data, where, and under which rules?”. An AI agent governance framework ensures these controls remain robust as automation scales.
3.1 Data ownership and accountability
For each critical domain:
- Is there a named business owner and data owner?
- Are they involved in approving new uses (training, inference, automation)?
- Do they understand sensitivity levels (PII, PCI, PHI, confidential) and regulatory constraints?
Without this clarity, “shadow automations” can emerge in high-risk domains (e.g., pricing overrides, credit decisions) without proper oversight.
3.2 Policies as code (not just PDFs)
Policies that live only in documents cannot protect you.
Check:
- Are access and masking rules enforced through IAM, data platforms, catalogues, and DLP — or only written down?
- Can you enforce:
- Purpose-based access (analytics vs operations)
- Field-level controls (masking, tokenisation)
- Region / residency constraints (UK GDPR, cross-border flows)
This becomes critical when agents access multiple systems within a single workflow.
3.3 Compliance and auditability
When an automated decision is questioned:
- Can you reconstruct which data, models, and rules were used at that time?
- Can you show an audit trail of who approved that automation and where human oversight sits?
- For high-impact decisions (credit, pricing, HR, healthcare), can you provide a meaningful explanation?
This is not a “nice to have”; it is a pre-requisite for scaling AI beyond pilots in regulated environments.
4. Integration and Architecture: Can Agents Safely Call Your World?
Most enterprises are not blocked by models; they’re blocked by how hard it is for any automation to call the right systems, in the right order, with the right contracts. Agents simply put more pressure on this. Agentic AI architecture consulting addresses the architectural maturity needed alongside technical capabilities.
4.1 API-first and event-driven access
Agents should behave like well-designed applications, not brittle screen-scrapers.
- Expose stable APIs for key business operations:
- Create / update entities (customers, orders, claims, invoices).
- Trigger workflows (approve refund, dispatch shipment, escalate case).
- Read status (order state, claim stage, risk assessment).
- Emit business events for critical actions:
- “Order placed”, “Payment failed”, “Refund requested”, “Claim submitted”, “Device alert raised”.
- Enforce versioning, authentication, and rate limits so agents can call these endpoints predictably and safely.
If your only integration surface is nightly files and UI macros, agents will be fragile and high-risk by design.
4.2 Decisions as first-class services
Agents don’t replace your business logic; they orchestrate decisions.
- Identify and expose decision services around which your processes revolve, for example:
- Approve / decline refund
- Flag high-risk transaction
- Prioritise ticket
- Select next best offer
- Wrap these decisions as APIs with clear contracts (inputs, outputs, confidence, and reasons where available).
- Internally, these services can use rules, models, heuristics, or a mix; externally, they should look like consistent, testable functions.
If decisions remain buried in UIs, spreadsheets, or monolithic code, agents will be limited to suggestions or unsafe workarounds.
4.3 Orchestration and tool registry
Agentic systems are orchestration-heavy: they call multiple tools, handle exceptions, and sometimes roll back actions.
Platform changes that help:
- Introduce a workflow / orchestration layer (or standardise on one) that supports:
- Multi-step workflows with retries and compensating actions.
- Explicit branching for “agent confident”, “uncertain → escalate”, “blocked → fallback”.
- Maintain a tool registry:
- Catalogue of callable tools (APIs, decision services, external connectors) with descriptions, owners, SLAs, cost, and risk classification.
- Versioning and deprecation policies so agents don’t call obsolete endpoints.
Agents should be configured against this registry, not handed raw URLs hidden in code.
4.4 Multi-domain and tenant isolation
In real enterprises, you rarely want a single agent to see and act on everything.
- Enforce domain and tenant boundaries in both your data platform and integration layer:
- Per brand, per region, per business unit where required.
- Apply row- and column-level security consistently:
- Not just for SQL queries, but also for vector search, semantic layer queries, and tool invocations.
- Design orchestration so that blast radius is limited: a misconfigured agent in one domain cannot cascade into others.
This is non-negotiable if you are a group with multiple regulated entities or a PE sponsor with several portfolio companies.
4.5 Schema, API and model evolution as a discipline
Agent workflows are brittle if schemas, APIs, and models change underneath them without warning.
Platform discipline:
- Schema evolution
- Prefer backward-compatible changes with deprecation windows.
- Use schema registries or contract tests for high-impact data products.
- API versioning
- No breaking changes without a new version; maintain old versions for a defined period while agents are migrated.
- Maintain older versions for a defined migration period.
- Model lifecycle
- Use a model registry with metadata, approval status, and rollout plans (canary, blue-green, rollback).
This is not just engineering hygiene; for agentic workflows that string together multiple tools and models, it is the difference between stable automation and constant firefighting.
5. Observability and Operations: Can You Keep Automation in Check?
Even with the right use cases, data and architecture, “set-and-forget” fails. Data shifts, user behaviour evolves, and regulations change.
5.1 Telemetry for data, services and decisions
Do you monitor:
- Data pipelines: latency, failure rates, freshness.
- APIs and services: availability, error rates, response times.
- Models and agents: input distributions, output patterns, drift indicators.
Beyond technical metrics, are business KPIs tied to automated decisions tracked and reviewed regularly? For example:
- Post-automation changes in refund approvals.
- Fraud hit rates.
- Manual audits.
- Exception volumes.
5.2 Incident response and safe fallbacks
When something goes wrong (and it will):
- Can you quickly disable or constrain an agent in a given domain or action type?
- Do you have safe fallback paths such as reverting to rules, manual review, or simpler models?
- Are runbooks clear — who gets paged, what gets rolled back, and how impact is assessed and communicated?
An agent-ready enterprise assumes failure and designs for graceful degradation, not hero debugging.
5.3 Continuous improvement loop
Automation is not a “launch and leave” effort.
Do you have a regular cadence (monthly or quarterly) where data, architecture, and business teams review:
- Performance metrics and ROI.
- Incidents and near-misses.
- Feedback from frontline users (contact centre, operations, finance).
Does this review feed into backlog prioritisation, retraining, and architecture improvements?
Without this loop, systems decay. With it, your AI footprint compounds value over time.

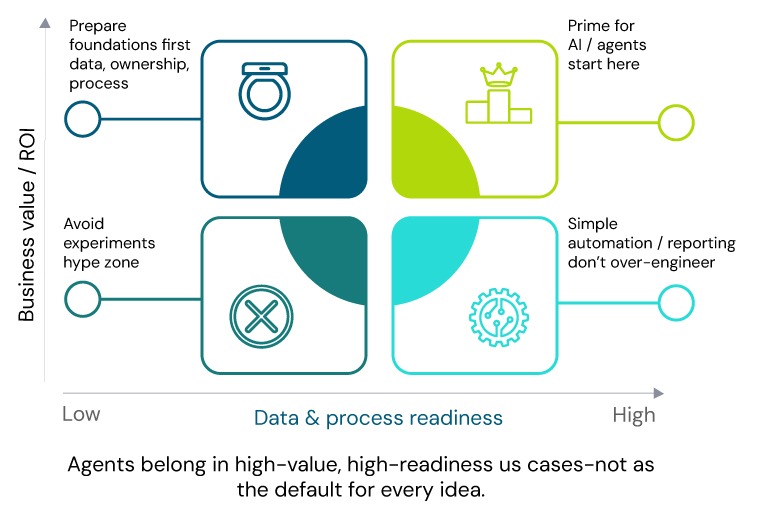
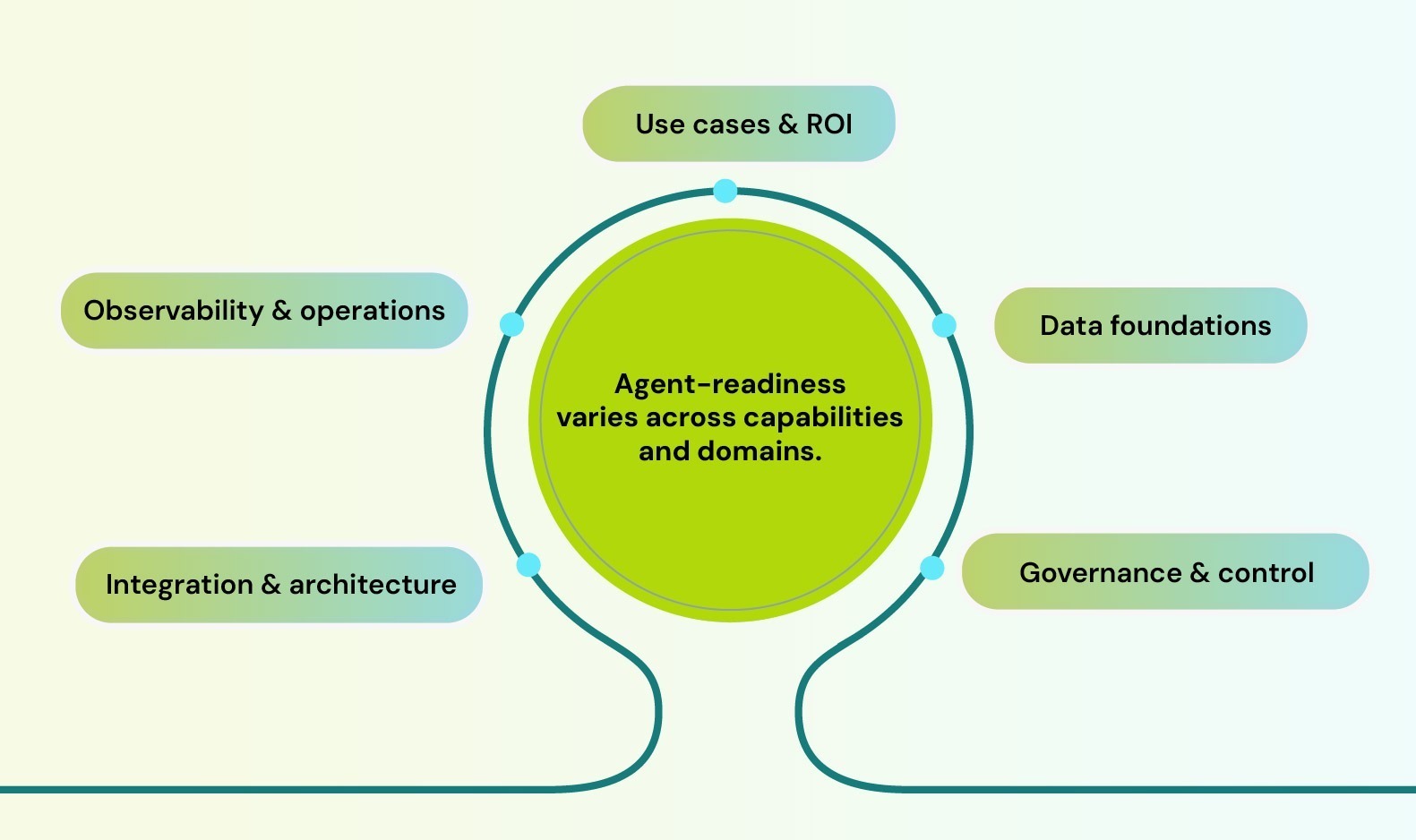
6. A Simple Agent-Readiness Score (Per Domain)
Turn the checklist into something you can act on.
For a given domain (e.g., refunds, fraud, invoicing, claims), score yourself from 1–5 on each dimension:
- Use cases & ROI
- Data foundations
- Governance & control
- Integration & architecture
- Observability & operations
Interpreting the score
- 4–5 – You’re ready to pilot and scale automation, including agents where appropriate, in this domain.
- 2–3 – You can start targeted pilots but should invest in foundational improvements in parallel.
- 1 – Fix fundamentals first; adding agents here will create more noise and risk than value.
Crucially, readiness is domain-specific: you might be agent-ready in fraud or customer service, but not in inventory or HR.
7. The Next 90 Days: A Practical Path
If you’re a CDO, CIO, CTO or value-creation leader wondering what to do with this:
- 1. Pick a small set of domains
- Choose 2–3 candidate areas (e.g., refunds, fraud, collections, claims, and invoice processing).
- 2. Apply the matrix and scoring
- Place each use case on the value vs readiness matrix.
- Score each domain across the five dimensions.
- 3. Commit to 1–2 foundational fixes
- For high-value / low-readiness domains, choose 1–2 concrete improvements (e.g., expose one key decision as an API, clean up customer identity, assign a data owner).
- 4. Design one “agent-ready” path end-to-end
- For at least one high-value, high-readiness domain, design the full path:
- Clear problem & ROI
- Data flows and controls
- Decision APIs
- Observability and runbooks
Agents may or may not be the right tool for that first journey—but if you make that journey “agent-ready” through enterprise AI pilot-to-production methodology, you also make it AI- and automation-ready in general.
8. ClairX’s Point of View
At ClairX, we come from data, engineering and enterprise architecture backgrounds. Our view is that Agentic AI is valuable when it orchestrates well-designed decisions and data flows; it is fragile and risky when used as a shortcut around unresolved fundamentals.
For most enterprises, becoming agent-ready does not mean rebuilding the data platform from scratch. It means enriching it with vector capabilities and a pragmatic semantic layer so that AI systems can find and understand the data they need.
When we work with mid- and large-scale enterprises across sectors:
- We start with use case and value clarity — no technology decisions until the problem and metrics are pinned down.
- We run data-first, architecture-driven readiness assessments using checklists like the one in this article.
- We design and implement solutions that treat agents as one of several AI clients on top of a robust, governed architecture.
- We stay cloud-native and vendor-agnostic, leveraging what hyperscalers and platforms already offer so your teams can focus on decisions, not plumbing.
In our experience, the enterprises that will win with agents are the ones that already take data, decisions and architecture seriously — long before a new buzzword arrives.
If you’d like to benchmark your current landscape against this checklist or run a focused agent-readiness / data-readiness assessment in a specific domain, we’d be happy to compare notes.

